
 The MLLP will be at the Third Conference in Machine Translation (WMT18), part of the EMNLP 2018 conference (Brussels, 31 October–4 November). We will present our article describing the German→English neural machine translation system with which we have ranked among the best in WMT18’s news translation shared task.
The MLLP will be at the Third Conference in Machine Translation (WMT18), part of the EMNLP 2018 conference (Brussels, 31 October–4 November). We will present our article describing the German→English neural machine translation system with which we have ranked among the best in WMT18’s news translation shared task.
The Third Conference in Machine Translation (WMT18), part of the EMNLP 2018 conference (Brussels, 31 October–4 November), builds on a series of annual workshops and conferences on statistical machine translation, going back to 2006. WMT organizes an annual shared task on machine translation of news in which the most important research groups in the area participate to show their advances each year. Update: You will find here the full WMT18 programme.
This year, the MLLP has participated in WMT18’s German→English news translation shared task with a newly built neural machine translation system. We are glad to report that our system ranked with the best in this year’s results, as can be seen in the table below (additionally, this year’s results can also be checked by automatic BLEU score here). Update: You will find here the complete results of WMT18’s news translation shared task.
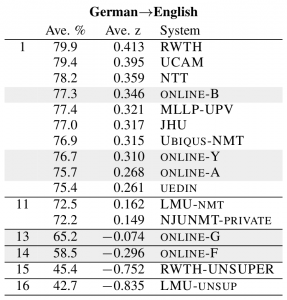
Results of WMT18 News Translation Task (human evaluation). The MLLP’s neural machine translation system ranked with the best.
MLLP researchers will be at WMT18 in Brussels (31 Oct–1 Nov) to present their article “The MLLP-UPV German-English Machine Translation System for WMT18”. The article’s authors, MLLP members Javier Iranzo-Sánchez, Pau Baquero-Arnal, Gonçal V. Garcés Díaz-Munío, Adrià Martínez-Villaronga, Jorge Civera and Alfons Juan, have summarized it in the following abstract:
This paper describes the statistical machine translation system built by the MLLP research group of Universitat Politècnica de València for the German>English news translation shared task of the EMNLP 2018 Third Conference on Machine Translation (WMT18). We used an ensemble of Transformer architecture–based neural machine translation systems. To train our system under “constrained” conditions, we filtered the provided parallel data with a scoring technique using character-based language models, and we added parallel data based on synthetic source sentences generated from the provided monolingual corpora.
Update: You will find here the full text and poster summary of our article.
We at the MLLP are glad to participate in this year’s WMT18. We look forward to seeing you there!