
 MLLP researchers participated in collaboration with RWTH Aachen colleagues in the IberSpeech-RTVE 2018 TV Speech-to-Text Challenge. We are proud to announce that our systems won both tracks of this international challenge on automatic transcription of TV shows.
MLLP researchers participated in collaboration with RWTH Aachen colleagues in the IberSpeech-RTVE 2018 TV Speech-to-Text Challenge. We are proud to announce that our systems won both tracks of this international challenge on automatic transcription of TV shows.
IberSPEECH 2018 (10th Jornadas en Tecnologías del Habla and 6th Iberian SLTech Workshop), held this year in Barcelona (Spain) on November 21–23, is the main international conference focused on research and industry/university collaboration around speech and language technologies on Iberian languages. It is also the context in which the long-running Albayzin evaluation challenges are held. This time, the Albayzin evaluation challenges 2018 have focused around TV broadcast content, based on a new, large, Spanish-language TV show corpus created in collaboration with Radio Televisión Española (RTVE).
For this occasion, MLLP researchers participated in collaboration with RWTH Aachen’s i6 Human Language Technology and Pattern Recognition Group in the IberSpeech-RTVE 2018 TV Speech-to-Text Challenge. This challenge focused on automatically transcribing different types of TV shows in Spanish, and had two independent tracks: closed conditions (where participants were limited to training their automatic speech recognition systems on the speech data provided by the organizers of the challenge) and open conditions (where participants were free to use any training data they had at their disposal). The results of this challenge were announced this week during IberSPEECH 2018.
We are proud to announce that our systems won both tracks (closed and open training conditions) of this international challenge on automatic transcription of Spanish-language TV shows.


In the following tables we can see the full results of both tracks of the challenge. Note that:
- The MLLP+RWTH-i6 team is team G7 in these tables.
- Team G14 was not considered for the final results of the closed conditions track, since they produced manual accurate transcriptions of the allowed training data, which meant they did not comply with the closed conditions. MLLP+RWTH-i6 (team G7) used automatically aligned and filtered audio, complying with the closed conditions, which made it the winner of the track.
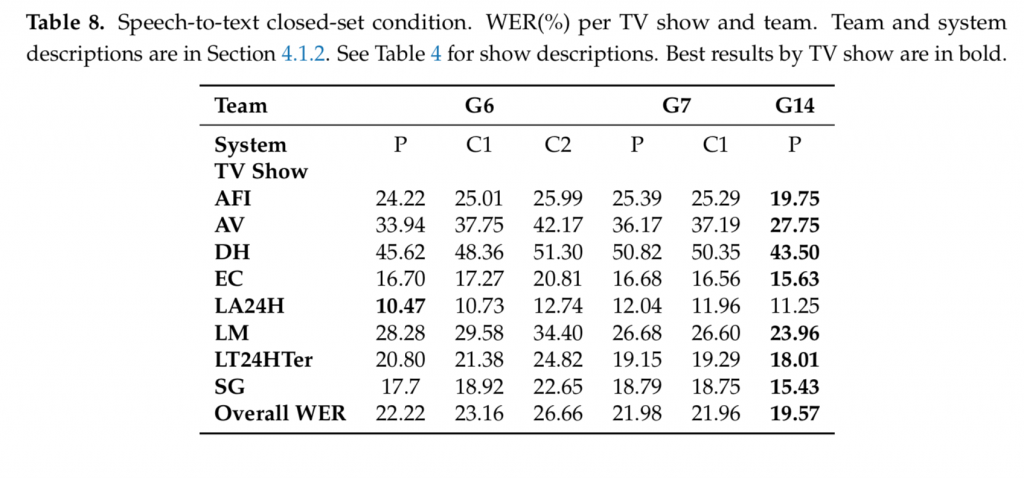
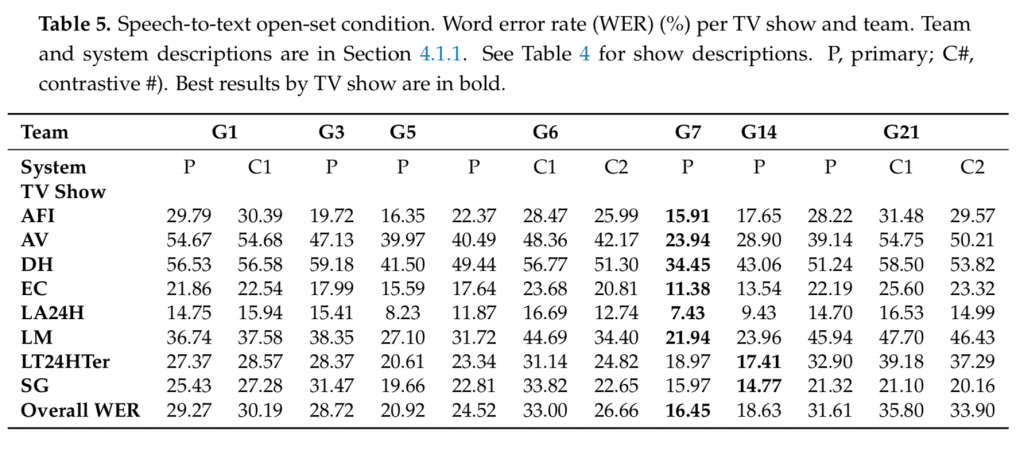
As a summary, the MLLP+RWTH-i6 team (team G7) were able to reduce the Word Error Rate (WER) of their automatic transcriptions to an overall 16.5% in the open conditions track, a significantly better figure with respect to those of other participants
The MLLP+RWTH-i6 winning ASR systems are described in the IberSPEECH 2018 article “MLLP-UPV and RWTH Aachen Spanish ASR Systems for the IberSpeech-RTVE 2018 Speech-to-Text Transcription Challenge”, by MLLP researchers Javier Jorge, Adrià Martínez-Villaronga, Adrià Giménez, Joan Albert Silvestre-Cerdà, Vicent Andreu Císcar, Alfons Juan and Albert Sanchis, together with RWTH-i6 researchers Pavel Golik, Patrick Doetsch and Hermann Ney.
A full account of the results for the IberSpeech-RTVE 2018 TV Speech-to-Text Challenge and the rest of the Albayzin evaluation challenges 2018 can be found in the article “Albayzin 2018 Evaluation: The IberSpeech-RTVE Challenge on Speech Technologies for Spanish Broadcast Media”, by the Albayzin 2018 organizers.
